首页
关于
论坛
投稿
搜索
文本建模
2019-08-07
1 / 1
统计应用
LDA-math-LDA 文本建模
靳志辉
/
2013-03-07
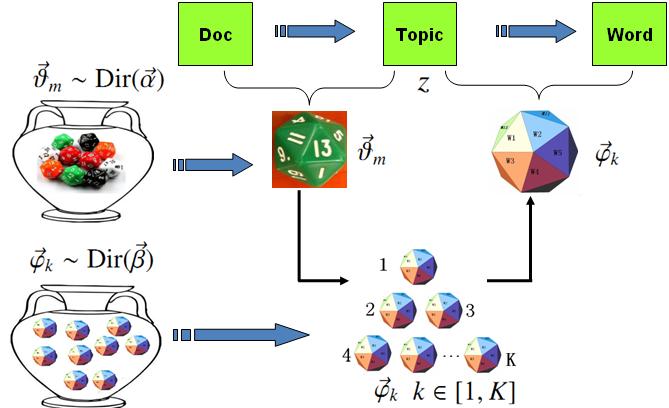
对于上述的 PLSA 模型,贝叶斯学派显然是有意见的,doc-topic 骰子$\overrightarrow{\theta}_m$和 topic-word 骰子$\overrightarrow{\varphi}_k$都是模型中的参数,参数都是随机变量,怎么能没有先验分布呢?于是,类似于对 Unigram Model 的贝叶斯改造, 我们也可以如下在两个骰子参数前加上先验分布从而把 PLSA 对应……
统计应用
LDA-math-文本建模
靳志辉
/
2013-03-07
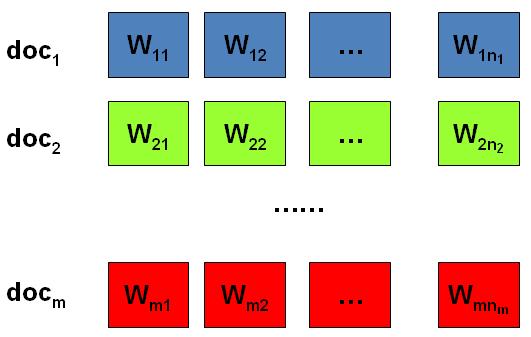
我们日常生活中总是产生大量的文本,如果每一个文本存储为一篇文档,那每篇文档从人的观察来说就是有序的词的序列$d=(w_1, w_2, \cdots, w_n)$。 包含$M$篇文档的语料库 统计文本建模的目的就是追问这些观察到语料库中的的词序列是如何生成的。统计学被人们描述为猜测上帝的游戏,人类产生的所有的语料文本我们都可以看成是一个伟大的上帝在天堂中抛掷骰子生成的,我们观察到的只是上帝玩这个游戏……