首页
关于
论坛
投稿
搜索
统计之都
2019-08-07
36 / 44
统计模型
从线性模型到广义线性模型(2)——参数估计、假设检验
张缔香
/
2011-01-31
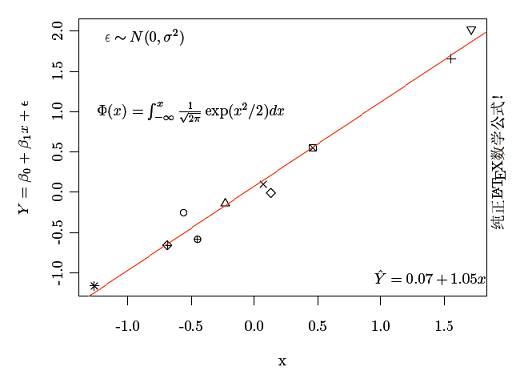
为了理论上简化,这里把GLM的分布限定在指数分布族。事实上,实际应用中使用最多的分布就是指数分布族,所以这样的简化可以节省很多理论上的冗长论述,也不会限制实际应用。 如前文如述,指数分布族的概率密度函数可以统一地写为: $$ f_Y(y;\theta,\Psi)=exp[(y\theta – b(\theta))/{\Psi} + c(y;\Psi)] $$ 这里为了在模型中体现散布参……
统计模型
一道抛硬币问题的不同解法和比较
魏太云
/
2011-01-22
[…] 本文针对求指定花样在抛硬币时首次出现时间期望的问题,分别从统计模拟、马氏过程、延迟更新过程、鞅、随机图等不同角度出发对该类问题进行了模拟和理论方面的解答,并展现了各种方法的特点和实用价值。 PDF全文下载: 本文PDF文档
统计模型
从线性模型到广义线性模型(1)——模型假设篇
张缔香
/
2011-01-18
在统计学里,对特定变量之间的关系进行建模、分析最常用的手段之一就是回归分析。回归分析的输出变量通常记做\( Y\),也称为因变量(dependent)、响应变量(response)、被解释变量(explained)、被预测变量(predicted)、从属变量(regressand);输入变量通常记做\( x_1\),…,\(x_p\),也称为自变量(independent)、控制变……
职业事业
统计学论文的发表流程、及统计学家的晋升和合作(内幕)
谢益辉
/
2011-01-15
这标题很吸引人,所有统计学相关领域的人可能都关心这几件事,但敬请降低对本文的期望。我不能再多说,否则要剧透了(看过的朋友也请不要剧透)。这段35分钟的视频讲述了统计学论文是如何发表的、统计学家在机构内如何得到晋升(影响晋升的指标),以及统计学家和生物学家如何交流和合作的种种“内幕”。新年伊始,我们也不想用大篇技术文章来“折磨”统计之都的读者们,那么,开始欣赏这部小电影吧: […] ……
统计应用
R软件在精算教学中的应用案例
张缔香
/
2011-01-12
本文作者为张缔香,文章由COS编辑部审核发表,略有修改。点击此处下载/阅读本文PDF版本 R软件做为一种统计软件,因其开源、免费、灵活的诸多优点得到越来越多的关注,无论网络上还是实体书店,关于R的教程铺天盖地,不甚枚举。因此,本文的目标不是做R的教程,而是将R和保险、精算教学结合起来,通过几个案例来说明R在保险、精算专业日常的教学和研究中可用之处。 作者在保险、精算的理论、专业知识方面水平有限,……
统计计算
Sweave后传:统计报告中的大规模计算与缓存
谢益辉
/
2011-01-03
学无止境。我曾以为我明白了如何在Sweave中使用缓存加快计算和图形,但后来发现我并没有真的理解,直到读了另外一些手册才明白,因此本文作为前文“Sweave:打造一个可重复的统计研究流程”之续集,向大家介绍一下如何在Sweave的计算和图形中使用缓存,以节省不必要的重复计算和作图,让那些涉及到密集型计算的用户不再对Sweave感到难堪。 如果你还没读前文,建议先从那里开始读,了解Sweave与“可……
统计软件
Think SAS(二)
胡江堂
/
2010-12-30
有个老本家,著有《白话文学史》(上卷)、《中国哲学史大纲》(上卷),——你知道他叫胡适。然后有朋友问这个“Think SAS”系列有没有下文,我自然不敢托大,“半卷先生”不能做,还是老老实实地把这个系列往前推吧。 第一篇“Think SAS”中的“Think”,纯粹做“考虑”解,说,诸君如果为工作计,不妨考虑下SAS。下面说些关于SAS本身的一些思考与认识。俗话说,人类一思考,上帝就拍砖。上一篇是……
R会议
第三届中国R语言会议(上海会场)纪要
邱怡轩
/
2010-11-22
本文撰稿:第三届中国R语言会议(上海会场)主席张翔。 第三届中国R语言会议上海会场合影(右键另存为看大图) 第三届中国R语言会议(上海会场)于2010年11月13日~14日在上海财经大学行政楼成功召开。会议由上海财经大学统计与管理学院与统计之都网站(cos.name)协办,由 Mango Solutions 提供赞助。在两天的会议时间里,来自各行各业的R用户齐聚上海,共同探讨和交流R软件的使用经……
统计模型
假设检验初步
胡江堂
/
2010-11-14
准备再尝试一下,用大白话叙述一遍统计推断中最基础的东西(假设检验、P值、……),算是把这段时间的阅读和思考做个梳理(东西不难,思考侧重在如何表述和展示)。这次打算用一种“迂回的”表达方式,比如,本文从我们的日常逻辑推理开始说起。 […] 复习一下普通逻辑的基本思路。假设以下陈述为真: […] 你打了某种疫苗P,就不会得某种流行病Q。 […] 我们把这个先决……
统计软件
Sweave:打造一个可重复的统计研究流程
谢益辉
/
2010-11-05
警告:本文提到的工具在更新中,请暂时不要按本文的配置去做,静候LyX 2.0.3的发布。 我们都痛恨统计造假。我们都对重复性的工作感到厌倦。如果你同意这两句话或这两句话适用于你的现状,那么本文将介绍一套开源、免费的工具来克服这两个问题。当然,前提是你愿意改变,这里的工具可以让这两种现象没有藏身之地,但无法改变造假和重复劳动的现实。以下为吊胃口视频(墙外观众可以看Vimeo;墙内看不到视频的可以任选……
统计模型
强大数定律与康托三分集
左辰
/
2010-10-13
首先从博雷尔正轨数定律(Borel’s Normal Number Theorem)说起。众所周知,(0,1]区间上的每一个实数\(\omega\)都与一列唯一的无穷的二进制展开序列\(\{X_k(\omega)\}\)一一对应,其中\(X_k (\omega)\)表示二进制展开的第k位,对应关系为: $$ \omega=\sum_{k=1}^n\frac{X_k(\omega)}{2^k} $$……
机器学习
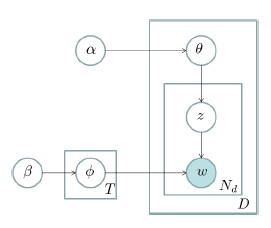
LDA主题模型简介
范建宁
/
2010-10-08
上个学期到现在陆陆续续研究了一下主题模型(topic model)这个东东。何谓“主题”呢?望文生义就知道是什么意思了,就是诸如一篇文章、一段话、一个句子所表达的中心思想。不过从统计模型的角度来说, 我们是用一个特定的词频分布来刻画主题的,并认为一篇文章、一段话、一个句子是从一个概率模型中生成的。 D. M. Blei在2003年(准确地说应该是2002年)提出的LDA(Latent……
««
«
1
2
3
…
35
36
37
…
44
»
»»